
To jest praktyczny przewodnik po tym, jak działa fundament internetu: adresowanie, routing, niezawodny transport i typowe pułapki, które pojawiają się przy diagnozowaniu sieci. Pokazuję tu nie tylko, czym jest model TCP/IP, ale też jak czytać jego warstwy, co dzieje się z danymi w trasie i jak odróżnić problem połączenia od błędu aplikacji. Jeśli chcesz rozumieć sieć bez wchodzenia od razu w ciężką teorię, jesteś w dobrym miejscu.
Najkrócej: to zestaw reguł, które sprawiają, że dane trafiają we właściwe miejsce
- Internet nie działa jako jeden protokół, tylko jako stos współpracujących warstw.
- IP odpowiada za adresowanie i trasowanie, a TCP za niezawodność, kolejność i potwierdzenia.
- Model ma cztery warstwy, a OSI siedem, więc oba opisy pokazują tę samą rzeczywistość z innej perspektywy.
- Najczęstsze problemy w praktyce to DNS, firewall, NAT, MTU i błędne założenie, że „brak internetu” oznacza awarię całej sieci.
- Gdy coś nie działa, najpierw sprawdzam adres IP, bramę, DNS i podstawową łączność, a dopiero potem aplikację.
Czym jest stos TCP/IP i dlaczego wciąż trzyma internet w ryzach
Najprościej widzę go jako podział pracy między kilka warstw. Jedna warstwa pilnuje, żeby urządzenie miało adres i trafiło w odpowiednią sieć, druga decyduje, jak dane mają być dostarczane, a trzecia dba o to, żeby aplikacja dostała wszystko w poprawnej kolejności. Dzięki temu przeglądarka, komunikator, poczta i VPN mogą działać równolegle na tym samym łączu, choć każdy z tych programów oczekuje czegoś trochę innego.
W praktyce to nie jest pojedynczy protokół, tylko zestaw współpracujących reguł komunikacji. Gdy wysyłasz stronę internetową, zdjęcie albo wiadomość, urządzenie nie „wrzuca tego do internetu” w jednym kawałku. Najpierw wybiera sposób transportu, potem dodaje adresy, a na końcu opakowuje dane tak, żeby kolejne urządzenia po drodze wiedziały, co z nimi zrobić. To właśnie dlatego ten model jest nadal tak ważny: jest prosty w założeniach, ale wystarczająco elastyczny, żeby obsługiwać zarówno domowe Wi-Fi, jak i duże sieci firmowe.
Ja zwykle tłumaczę to tak: jeśli internet jest systemem pocztowym, to IP jest adresem na kopercie, a TCP pilnuje, czy list dotarł w całości i w odpowiedniej kolejności. Żeby to zobaczyć bez skrótów, rozbijmy model na warstwy.
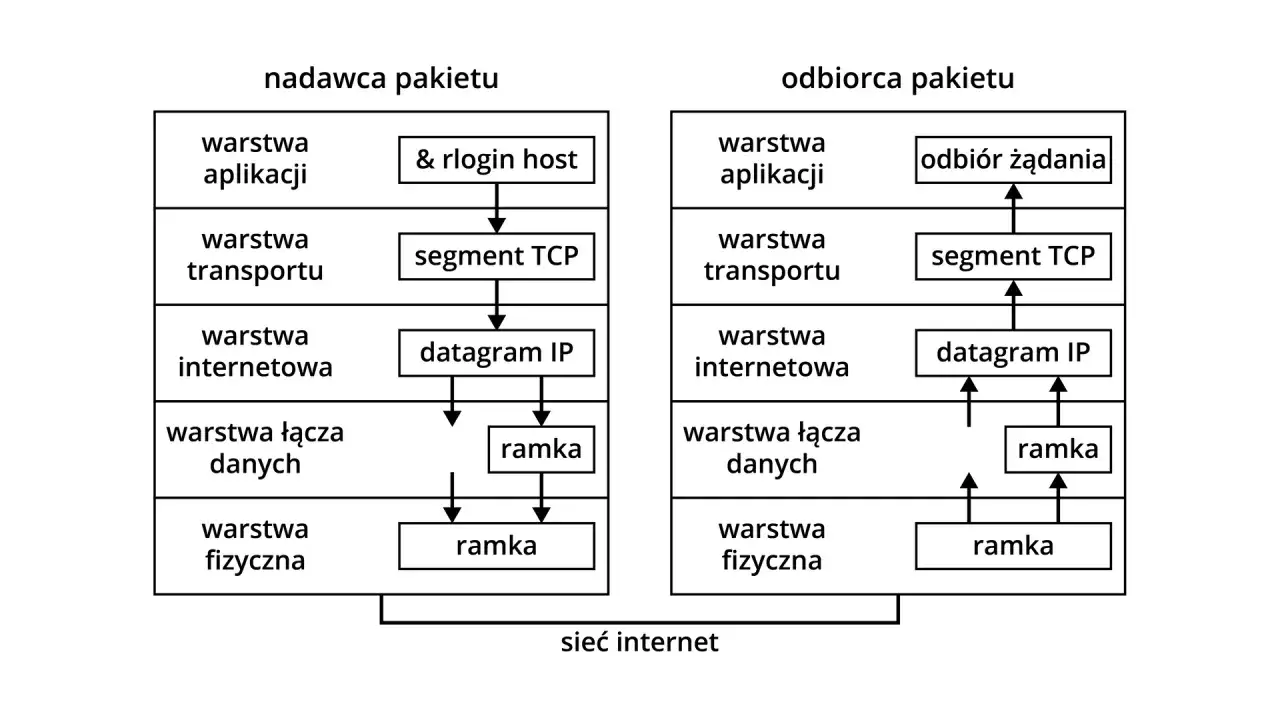
Jak działają warstwy tego modelu
Model TCP/IP ma cztery praktyczne warstwy. To uproszczenie względem OSI, ale bardzo użyteczne, bo pozwala szybko wskazać, gdzie leży problem: w aplikacji, transporcie, routingu czy samej transmisji fizycznej.
| Warstwa | Co robi | Przykłady |
|---|---|---|
| Aplikacji | Określa, jak programy wymieniają dane i w jakim formacie je rozumieją. | HTTP, HTTPS, DNS, SMTP, SSH |
| Transportu | Dba o porty, dzielenie danych na mniejsze części, kolejność i potwierdzenia. | TCP, UDP |
| Internetu | Odpowiada za adresy IP, trasowanie i przekazywanie pakietów między sieciami. | IP, ICMP |
| Dostępu do sieci | Przesyła dane w konkretnej sieci lokalnej, np. po Wi-Fi albo Ethernet. | Ethernet, Wi-Fi, światłowód |
Najważniejsze jest to, że każda warstwa widzi inny fragment zadania. Aplikacja myśli o treści, transport o porcie i niezawodności, warstwa internetowa o adresie i trasie, a warstwa dostępu do sieci o realnym medium, którym płynie sygnał. OSI opisuje to bardziej szczegółowo, ale do codziennej pracy i diagnozy awarii ta czterowarstwowa perspektywa zwykle wystarcza.
Warto też pamiętać, że routery nie analizują pełnej treści wiadomości tak, jak robi to aplikacja. One patrzą głównie na nagłówek IP i decydują, którędy przesłać pakiet dalej. Dzięki temu sieć skaluje się na ogromną liczbę urządzeń, a nie tylko na małe, lokalne segmenty. Następny krok to zobaczyć, co dzieje się z danymi w chwili wysyłki.
Co dzieje się z danymi podczas transmisji
Gdy otwierasz stronę albo wysyłasz plik, proces wygląda mniej więcej tak:
- Aplikacja tworzy dane, które mają zostać przesłane, na przykład zapytanie do serwera.
- Warstwa transportu rozdziela je na segmenty i przypisuje porty, czyli numery mówiące, do której usługi mają trafić dane. Porty mieszczą się w zakresie 0-65535, a część z nich jest standardowo zarezerwowana dla znanych usług.
- TCP, jeśli jest używany, dodaje numerację segmentów, potwierdzenia odbioru i mechanizmy ponawiania, żeby odzyskać brakujące fragmenty.
- Warstwa IP dokłada adres źródłowy i docelowy, a potem wybiera drogę przez kolejne sieci.
- Warstwa dostępu do sieci zamienia wszystko w ramki i wysyła sygnał przez konkretne medium, na przykład kabel lub Wi-Fi.
- Po drodze routery przekazują pakiety dalej, aż trafią do celu.
- Odbiorca składa dane z powrotem w całość i przekazuje je aplikacji.
Przed właściwą wymianą danych TCP zwykle wykonuje jeszcze trzyetapowe uzgadnianie połączenia, czyli handshake: SYN, SYN-ACK i ACK. To prosty, ale bardzo ważny mechanizm, bo pozwala obu stronom ustalić, że druga strona istnieje i jest gotowa na rozmowę. W efekcie połączenie jest bardziej przewidywalne niż zwykłe „wyślij i liczę na szczęście”.
W praktyce widzę tu też źródło wielu nieporozumień. Pakiet nie musi iść zawsze tą samą trasą, router nie musi znać całej treści wiadomości, a błędy często powstają nie tam, gdzie użytkownik je odczuwa. To prowadzi do pytania, czym różni się transport niezawodny od szybkiego, ale lżejszego.
TCP, UDP, IPv4 i IPv6 w praktyce
TCP i UDP robią różną robotę
| Cecha | TCP | UDP |
|---|---|---|
| Niezawodność | Tak, zapewnia potwierdzenia i ponawia brakujące dane. | Nie, wysyła bez gwarancji dostarczenia. |
| Kolejność danych | Zachowuje kolejność segmentów. | Nie daje takiej gwarancji. |
| Narzut | Większy, bo kontroluje połączenie i transmisję. | Mniejszy, więc bywa lepszy przy czasie rzeczywistym. |
| Typowe zastosowania | WWW, poczta, transfer plików, logowanie do serwerów. | Streaming, VoIP, gry sieciowe, DNS w wielu scenariuszach. |
Jeżeli aplikacja potrzebuje pewności, że każdy bajt dotrze w poprawnej kolejności, wybiera TCP. Jeśli ważniejsza jest szybkość reakcji niż perfekcyjna kompletność, często lepszy będzie UDP. To nie znaczy, że UDP jest „gorszy”; on po prostu rozwiązuje inny problem.
Przeczytaj również: Motywacja co to - Klucz do zrozumienia Twoich działań i celów
IPv4 i IPv6 rozwiązują ten sam problem inaczej
- IPv4 używa adresów 32-bitowych, więc pula adresów jest ograniczona. Właśnie dlatego przez lata pojawiały się mechanizmy takie jak NAT, które pozwoliły „dzielić” jeden publiczny adres między wiele urządzeń.
- IPv6 ma adresy 128-bitowe, więc przestrzeń adresowa jest ogromna i praktycznie usuwa problem wyczerpania adresów.
- W realnych sieciach często spotyka się dual-stack, czyli równoległe użycie IPv4 i IPv6. To kompromis, który ułatwia przejście na nowszy standard bez wywracania infrastruktury.
- Dla użytkownika końcowego różnica bywa niewidoczna, ale dla administratora ma znaczenie przy routingu, regułach firewalla i diagnostyce połączeń.
Tu jest ważna rzecz: NAT pomagał utrzymać IPv4 przy życiu, ale nie jest substytutem nowej puli adresów. Dla bezpieczeństwa sieci liczą się reguły, segmentacja i polityki dostępu, a nie sam fakt, że urządzenie siedzi „za NAT-em”. Kiedy to rozumiesz, łatwiej wyłapać błędy, które ludzie mylą z awarią internetu.
Najczęstsze błędy, które psują diagnozę sieci
W codziennej pracy najczęściej widzę nie problem z samym protokołem, ale z błędną interpretacją objawów. Oto pułapki, które wracają najczęściej:
- Mylenie braku internetu z problemem Wi-Fi - sygnał bezprzewodowy może być dobry, a awaria leży w DNS, bramie albo połączeniu z operatorem.
- Zakładanie, że ping wszystko pokaże - odpowiedź na ping mówi tylko, że ICMP przechodzi, a nie że aplikacja, port czy certyfikat działają poprawnie.
- Ignorowanie DNS - strona może nie działać po nazwie domenowej, mimo że po adresie IP odpowiada bez problemu.
- Firewall blokujący port - usługa działa, ale ruch na właściwym porcie jest odcinany po drodze.
- Problem z MTU - pakiety są zbyt duże dla fragmentu trasy i znikają po drodze albo powodują bardzo dziwne objawy.
- Pomijanie NAT i tras - to, że urządzenie ma adres prywatny, nie znaczy jeszcze, że dotrze do internetu bez poprawnej bramy i routingu.
Gdy coś nie działa, zaczynam od prostego zestawu pytań: czy urządzenie ma adres IP, czy widzi bramę domyślną, czy działa DNS i czy można przejść dalej niż lokalna sieć. Potem sprawdzam trasę pakietu narzędziami typu traceroute i patrzę, gdzie ruch się zatrzymuje. W wielu przypadkach to oszczędza więcej czasu niż chaotyczne klikanie w ustawieniach.
Najbardziej praktyczna zasada jest zaskakująco prosta: najpierw potwierdź łączność, potem nazwę, na końcu aplikację. Jeśli przejdziesz tę kolejność bez zgadywania, zwykle szybciej trafisz w sedno problemu. I właśnie dlatego ten model jest tak użyteczny nie tylko w teorii, ale też przy realnym rozwiązywaniu awarii.
Co warto zapamiętać, zanim zaczniesz grzebać w ustawieniach
Jeżeli mam zostawić tylko kilka rzeczy, to te są najcenniejsze: sprawdzaj adres, bramę, DNS i port, zanim uznasz, że zawinił „internet”. Patrz na objawy warstwowo, bo sieć lubi mylić tropy: czasem problem zaczyna się w Wi-Fi, a kończy w aplikacji, a czasem jest dokładnie odwrotnie.
W praktyce najbardziej pomagają trzy nawyki: notowanie dokładnego momentu awarii, porównywanie zachowania po kablu i po Wi-Fi oraz sprawdzanie, czy problem dotyczy jednej usługi, czy całego połączenia. To są drobiazgi, ale właśnie one pozwalają odróżnić przypadkowy glitch od błędu konfiguracji albo ograniczenia po stronie infrastruktury.
Jeśli chcesz lepiej rozumieć sieci komputerowe, zacznij nie od zapamiętywania skrótów, tylko od relacji między warstwami. Gdy ten układ wskoczy na miejsce, TCP, IP, porty, routing i diagnostyka przestają wyglądać jak chaos, a zaczynają tworzyć sensowny system.