TCP, czyli Transmission Control Protocol, to jeden z tych protokołów, których nie widać, ale które trzymają internet w ryzach: dba o kolejność danych, potwierdzenia odbioru, retransmisje i kontrolę przeciążenia. W tym tekście rozkładam go na części pierwsze bez nadmiaru teorii, tak żeby było jasne, kiedy pomaga, kiedy spowalnia i dlaczego wciąż ma znaczenie mimo rozwoju nowszych technologii. Dorzucam też praktyczne wskazówki, które przydają się przy diagnozowaniu połączeń i projektowaniu usług sieciowych.
Najkrócej TCP daje niezawodność, kolejność i kontrolę, ale za cenę narzutu
- Przesyła strumień bajtów, a nie gotowe wiadomości, więc aplikacja musi sama złożyć sensowną całość.
- Połączenie startuje od three-way handshake, który synchronizuje obie strony i zmniejsza ryzyko pomyłek.
- ACK, retransmisje i okna odbioru sprawiają, że dane docierają w kolejności i bez utraty fragmentów.
- Wydajność kosztuje tu więcej niż w UDP, ale w zamian dostajesz stabilność i prostsze zachowanie aplikacji.
- W nowoczesnym webie coraz częściej pojawia się QUIC, lecz TCP nadal napędza wiele usług, od SSH po klasyczne API.
Czym jest TCP i gdzie leży w stosie sieciowym
Gdy tłumaczę ten protokół prosto, zaczynam od jednego zdania: TCP nie przesyła „wiadomości”, tylko uporządkowany strumień bajtów. To warstwa transportowa między aplikacją a siecią IP, która pilnuje, żeby obie strony rozmowy widziały te same dane w tej samej kolejności.
W praktyce oznacza to kilka rzeczy naraz: dane są dzielone na segmenty, każdy segment może zostać potwierdzony, a jeśli coś zniknie po drodze, następuje retransmisja. Aplikacja dostaje więc coś bardziej przewidywalnego niż surowy ruch sieciowy, ale płaci za to dodatkowym narzutem.
- Połączenie jest stanowe - obie strony pamiętają, że rozmowa trwa.
- Liczy się kolejność - odbiorca składa strumień z segmentów w odpowiednim porządku.
- Ważne są porty - to one pozwalają odróżnić jedną usługę od drugiej na tym samym hoście.
- To dobry wybór dla usług, które nie mogą zgubić danych - API, SSH, poczta, transfer plików, bazy danych.
Z mojego punktu widzenia to właśnie tutaj zaczyna się praktyka: nie pytam najpierw, czy protokół jest „szybki”, tylko czy zapewnia taki model komunikacji, jakiego naprawdę potrzebuje aplikacja. Skoro to jasne, łatwiej przejść do zestawiania sesji, czyli momentu, w którym wszystko się zaczyna.
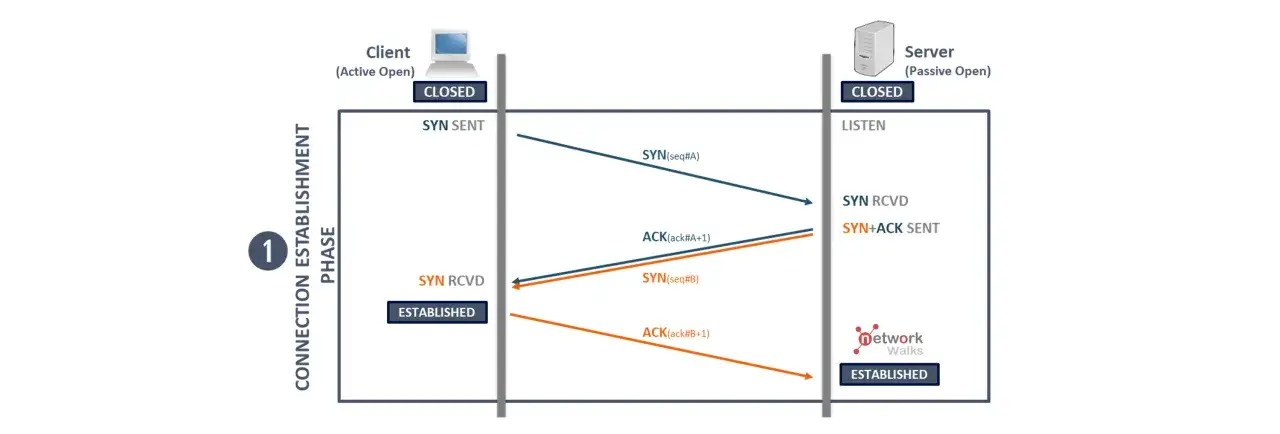
Jak zestawiane i zamykane jest połączenie
Najbardziej znany element tego protokołu to three-way handshake, czyli trzyetapowe uzgadnianie połączenia. To nie jest formalność dla formalności, tylko sposób na zsynchronizowanie numerów sekwencyjnych i odróżnienie nowej sesji od spóźnionych segmentów z poprzedniej.
- SYN - jedna strona zgłasza chęć połączenia i podaje swój początkowy numer sekwencyjny.
- SYN-ACK - druga strona potwierdza żądanie i wysyła własny numer sekwencyjny.
- ACK - pierwsza strona potwierdza odbiór i od tego momentu można wysyłać dane.
W praktyce to ważne, bo zanim aplikacja zacznie wysyłać właściwy ruch, obie strony muszą zgodzić się co do stanu połączenia. To dlatego pierwsze pakiety są droższe od zwykłego przesyłu danych, zwłaszcza przy wysokiej latencji.
Zamykanie działa podobnie metodycznie. Zwykle kończy się wymianą FIN i ACK, a jedna ze stron może wejść w stan TIME-WAIT, żeby upewnić się, że opóźnione segmenty z poprzedniej sesji nie popsują nowego połączenia. Dla osoby diagnozującej sieć to często jest klucz do zrozumienia, dlaczego „zamknięte” nie zawsze znaczy „zniknęło natychmiast”.
Po takim starcie można już sensownie przyjrzeć się temu, co protokół robi przez całą resztę życia połączenia, czyli jak pilnuje dostarczenia danych bez chaosu.
Co sprawia, że dane docierają w odpowiedniej kolejności
Tu zaczyna się najciekawsza część. Niezawodność TCP nie polega na magii, tylko na kilku prostych mechanizmach, które razem robią porządek z ruchem sieciowym.
Numeracja i potwierdzenia
Każdy segment dostaje numer sekwencyjny, a odbiorca odsyła ACK, czyli potwierdzenie odebrania danych do konkretnego miejsca w strumieniu. Dzięki temu nadawca wie, co doszło, a co trzeba wysłać ponownie. Jeśli segmenty dotrą w złej kolejności, odbiorca nie miesza ich z treścią aplikacji, tylko składa całość dopiero wtedy, gdy ma komplet.
Retransmisje
Gdy potwierdzenie nie nadejdzie na czas, nadawca zakłada utratę pakietu i retransmituje brakujący fragment. To właśnie dlatego TCP tak dobrze sprawdza się przy plikach, dokumentach, logowaniu do serwera czy pracy z API, gdzie utrata pojedynczego kawałka danych byłaby realnym problemem.
Przeczytaj również: Jak odzyskać plik Excel - skuteczne metody na przywrócenie danych
Okna i kontrola przeciążenia
Tu łatwo pomylić dwa podobne pojęcia. Okno odbioru mówi, ile danych druga strona jest w stanie przyjąć, a kontrola przeciążenia mówi, jak agresywnie wolno obciążać samą sieć. W praktyce protokół zaczyna ostrożnie, potem zwiększa tempo i reaguje na straty. W standardowych algorytmach mieszczą się m.in. slow start, congestion avoidance, fast retransmit i fast recovery. To rozsądny kompromis: lepsza stabilność, ale nie zawsze maksymalna prędkość.
Właśnie ten kompromis najlepiej widać, gdy porównam go z lżejszymi rozwiązaniami, bo wtedy staje się jasne, kiedy TCP jest zaletą, a kiedy kulą u nogi.
TCP kontra UDP i QUIC w praktyce
Najczęstszy błąd początkujących to traktowanie tego protokołu jako domyślnego wyboru do wszystkiego. Ja wolę patrzeć na niego jak na narzędzie do zadań, w których ważniejsze są pewność i porządek niż absolutnie najniższa latencja.
| Protokół | Kiedy sprawdza się najlepiej | Plusy | Ograniczenia |
|---|---|---|---|
| TCP | API, SSH, poczta, transfer plików, systemy transakcyjne | Niezawodność, zachowanie kolejności, retransmisje, kontrola przeciążenia | Większy narzut, stan połączenia, możliwe blokowanie całego strumienia po utracie segmentu |
| UDP | VoIP, gry online, telemetria, streaming, ruch, w którym liczy się reakcja | Mały narzut, prostota, niższa latencja | Brak gwarancji dostarczenia i kolejności, odpowiedzialność za korekcję spada na aplikację |
| QUIC | HTTP/3 i nowoczesny web, gdzie ważne są szybki start i mniejsza latencja | Pracuje nad UDP, skraca zestawianie połączenia, ogranicza blokowanie wielu strumieni przez jedną utratę pakietu | Nie wszędzie dostępny, wymaga wsparcia po obu stronach stosu i nie zastępuje TCP w każdym scenariuszu |
Jeśli priorytetem jest integralność danych, TCP nadal pozostaje bardzo mocnym wyborem. Jeśli aplikacja potrafi sama obsłużyć utraty albo potrzebuje szybszej reakcji niż pełnej niezawodności, lepiej spojrzeć na UDP lub QUIC. W nowoczesnym webie HTTP/3 korzysta z QUIC właśnie po to, by skrócić zestawianie i zmniejszyć problem blokowania całego ruchu przez pojedynczą utratę segmentu.
Na takim tle dużo łatwiej zrozumieć, dlaczego część problemów z siecią wygląda jak awaria, chociaż w praktyce jest tylko konsekwencją działania transportu.
Typowe problemy, które wyglądają na awarię sieci
Gdy połączenie nie działa, wina nie musi leżeć w aplikacji. Z mojej praktyki najwięcej czasu oszczędza szybkie rozpoznanie, na jakim etapie sesja się zatrzymuje.
| Objaw | Najczęstsza przyczyna | Co sprawdzam najpierw |
|---|---|---|
Connection refused |
Serwis nie nasłuchuje na porcie albo aktywnie odrzuca połączenie | Proces aplikacji, numer portu, reguły firewalla i ACL |
| Połączenie wisi na etapie SYN | Firewall, NAT, routing, utrata pakietów lub przeciążenie po drodze | Trasę, filtry, dostępność portu i ogólny packet loss |
| Częste retransmisje | Straty pakietów, słabe Wi-Fi, przeciążony link, problem z jakością łącza | Opóźnienia, utratę pakietów, stan interfejsów i obciążenie sieci |
Dużo stanów TIME-WAIT
|
Normalny efekt częstego zamykania krótkich połączeń | Churn połączeń, pooling, keep-alive i sposób pracy aplikacji |
Gwałtowny RST
|
Serwer, proxy albo load balancer zamknął sesję bez klasycznego wygaszania | Timeouty, limity, błędy aplikacji i polityki pośredników |
Na Linuxie często zaczynam od ss -tan albo krótkiego śladu pakietów, bo same logi aplikacji nie pokazują retransmisji i timeoutów. Gdy te symptomy umiesz rozpoznać, diagnoza przestaje być zgadywaniem, a staje się zwykłą analizą stanu połączenia.
Jak projektować usługi, żeby nie płacić za niepotrzebny narzut
Jeśli projektuję usługę, najpierw liczę koszt połączeń, a dopiero potem zastanawiam się nad przepustowością. To proste przesunięcie perspektywy często daje większy efekt niż jakakolwiek mikrooptymalizacja po stronie kodu.
- Utrzymuj połączenia, zamiast je bez przerwy otwierać i zamykać - keep-alive i pooling zmniejszają koszt handshake.
- Unikaj nadmiernie „gadatliwych” API - wiele małych żądań zwiększa liczbę ACK-ów i opóźnień.
- Patrz na limity infrastruktury - deskryptory plików, timeouty load balancera, kolejki, liczba portów efemerycznych.
- Na łączach mobilnych i dalekich trasach licz się z większym kosztem narzutu - każde opóźnienie handshaku i retransmisji boli bardziej niż w sieci lokalnej.
- Jeśli ruch ma charakter czasu rzeczywistego, rozważ, czy nie lepiej oprzeć się na UDP albo HTTP/3 z QUIC.
W praktyce najwięcej zysku daje nie tyle „wyciśnięcie” z TCP każdej milisekundy, ile dobranie takiej architektury ruchu, by protokół nie musiał ciągle walczyć z własnymi ograniczeniami. Z tego już bardzo blisko do jednego prostego wniosku: nie każdy problem sieciowy rozwiązuje się tym samym transportem.
Jak wybrać właściwy transport bez zgadywania
- TCP wybieraj wtedy, gdy ważniejsze są porządek, pewność dostarczenia i prostszy model po stronie aplikacji.
- Sięgaj po lżejsze rozwiązania, gdy opóźnienie ma większe znaczenie niż pełna niezawodność albo gdy aplikacja sama potrafi obsłużyć straty.
- Jeśli sieć zaczyna sprawiać problemy, patrz najpierw na liczbę połączeń, retransmisje, timeouty i zachowanie po zamknięciu sesji.
Najlepiej myśleć o tym protokole nie jak o jedynym słusznym wyborze, tylko jak o świadomym kompromisie między niezawodnością a szybkością. Kiedy rozumiesz ten kompromis, łatwiej zbudować usługę, która działa stabilnie, nie marnuje zasobów i nie zaskakuje użytkownika w najmniej odpowiednim momencie.