
Najważniejsze rzeczy, które warto wiedzieć o modelu relacyjnym
- Dane są trzymane w tabelach, a ich powiązania budują klucze główne i obce.
- SQL pozwala łączyć tabele, filtrować rekordy i robić agregacje, które są podstawą raportowania.
- Największą przewagą tego podejścia jest spójność danych i kontrola jakości.
- Przy analizie liczy się nie tylko struktura tabel, ale też indeksy, widoki i sensowny podział na warstwę operacyjną oraz raportową.
- Zbyt agresywna normalizacja poprawia porządek, ale może spowolnić cięższe zapytania analityczne.
- W wielu projektach najlepszy efekt daje nie czysty model, lecz dobrze przemyślany kompromis między porządkiem a wydajnością.
Czym jest model relacyjny i z czego się składa
Model relacyjny opiera się na prostej, ale bardzo mocnej zasadzie: informacje zapisuje się w tabelach, a każda tabela opisuje jeden rodzaj obiektu lub zdarzenia. W praktyce oznacza to osobne zbiory dla klientów, zamówień, produktów, płatności czy transakcji. Dzięki temu dane nie rozlewają się po systemie w przypadkowy sposób, tylko tworzą logiczną strukturę, którą da się utrzymać i rozwijać.
Najważniejsze elementy są tu dobrze znane, ale ich rola w analizie bywa niedoceniana. Klucz główny identyfikuje rekord jednoznacznie, a klucz obcy łączy jedną tabelę z drugą. Do tego dochodzą ograniczenia poprawności, takie jak unikalność wartości czy zakaz pustych rekordów tam, gdzie nie ma to sensu. To właśnie one chronią analizę przed sytuacją, w której jeden klient występuje kilka razy pod różnymi identyfikatorami albo jedno zamówienie nie ma przypisanej płatności.
| Pojęcie | Co oznacza | Po co jest ważne w analizie |
|---|---|---|
| Tabela | Zbiór rekordów opisujących jeden typ danych | Porządkuje dane i ułatwia ich filtrowanie |
| Klucz główny | Jednoznaczny identyfikator rekordu | Zapobiega duplikatom i ułatwia łączenie danych |
| Klucz obcy | Odwołanie do rekordu w innej tabeli | Buduje relacje potrzebne do raportów wielotabelowych |
| Indeks | Struktura przyspieszająca wyszukiwanie | Pomaga przy filtrach, sortowaniu i joinach |
| Widok | Zapisane zapytanie pokazujące dane w gotowej formie | Upraszcza raportowanie i standaryzuje logikę biznesową |
Jeśli ktoś zaczyna od zbyt ogólnej definicji, łatwo przeoczyć sedno: ten model nie jest tylko sposobem przechowywania informacji, ale sposobem myślenia o tym, jak dane będą później używane. I właśnie dlatego przejście od struktury tabel do raportowania jest tak ważne.
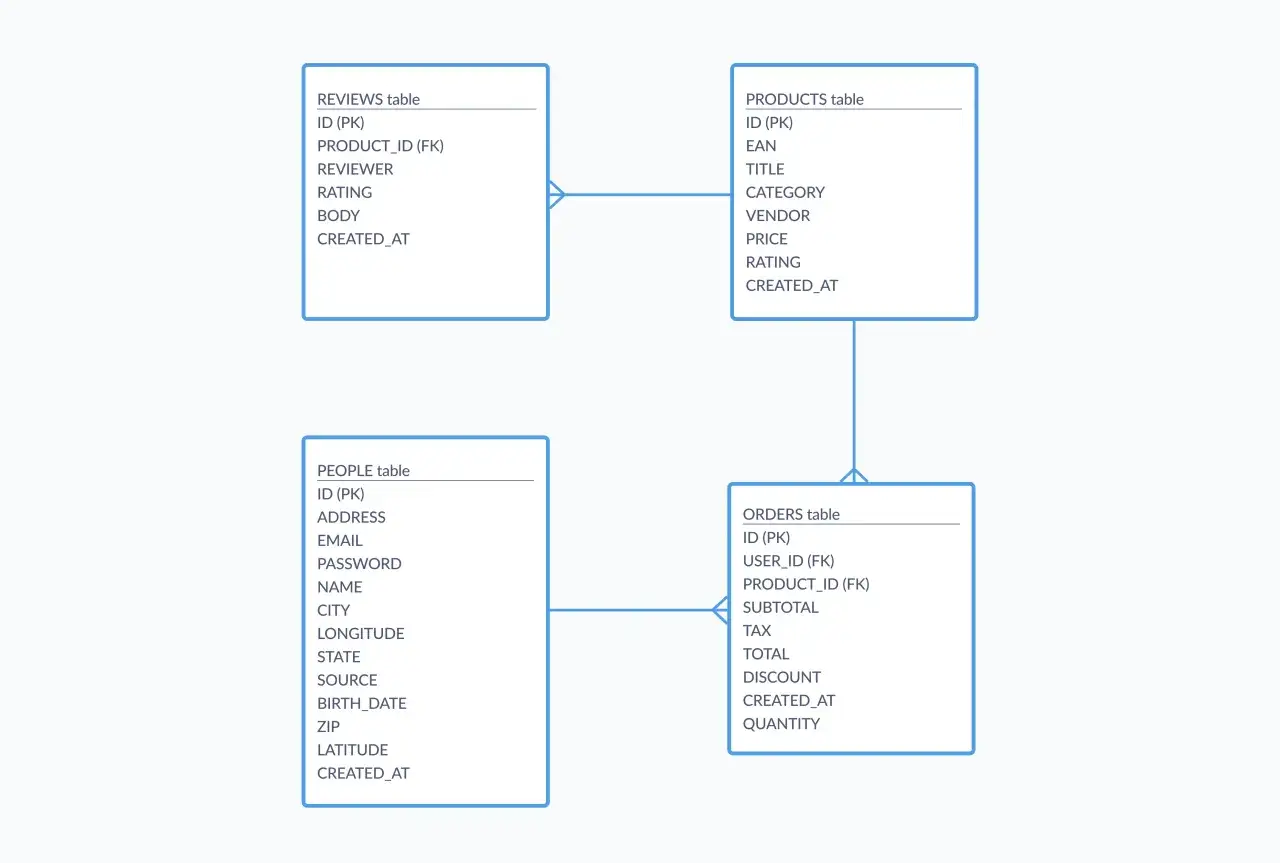
Jak model tabel wspiera raporty i analizy
W analizie danych najbardziej liczy się to, czy da się szybko odpowiedzieć na pytania typu: kto kupuje najczęściej, które produkty generują największy przychód, jak zmienia się konwersja w czasie albo gdzie pojawiają się spadki jakości. Model relacyjny dobrze sobie z tym radzi, bo umożliwia łączenie informacji z wielu tabel bez kopiowania wszystkiego do jednego wielkiego arkusza.
Ja zwykle pokazuję to na prostym przykładzie sklepu internetowego. Zamówienia są w jednej tabeli, pozycje zamówień w drugiej, klienci w trzeciej, a produkty w czwartej. Dzięki temu jedno zapytanie SQL może zestawić sprzedaż z danymi klienta, regionem, kategorią produktu albo kanałem pozyskania. To jest ogromna przewaga, bo analiza nie opiera się na zgadywaniu, tylko na spójnych relacjach między tabelami.
- JOIN pozwala połączyć dane z kilku tabel i odtworzyć pełny obraz zdarzenia.
- GROUP BY umożliwia agregację, czyli zliczanie, sumowanie i porównywanie wyników.
- WHERE zawęża dane do konkretnego okresu, produktu, działu lub klienta.
- Widoki upraszczają raporty, bo chowają złożone logiki zapytań przed użytkownikiem końcowym.
- Ograniczenia integralności dbają o to, żeby raport nie opierał się na błędnych lub niepełnych rekordach.
W praktyce najczęściej wygrywa tu nie samo „posiadanie bazy”, ale to, że dane są przewidywalne. Jeśli tabela klientów ma jeden rekord na osobę, a tabela zamówień jasno wskazuje, do kogo należy transakcja, analityk może skupić się na wnioskach zamiast na czyszczeniu chaosu. To prowadzi prosto do pytania, kiedy taki model jest najlepszym wyborem, a kiedy zaczyna ograniczać.
Kiedy ten model daje przewagę, a kiedy zaczyna przeszkadzać
Relacyjny model najmocniej błyszczy tam, gdzie dane mają jasną strukturę i muszą być poprawne w momencie zapisu. Dlatego dobrze sprawdza się w finansach, e-commerce, systemach zamówień, CRM, księgowości czy raportowaniu operacyjnym. W tych środowiskach spójność jest ważniejsza niż swoboda schematu. Jeśli jedna płatność nie zgadza się z zamówieniem, problem nie kończy się na wykresie, tylko dotyka procesu biznesowego.
W analizie pojawia się jednak kompromis. Im bardziej rozdrobnione tabele i im więcej relacji, tym częściej rośnie koszt złożonych zapytań. Przy lekkich raportach to nie przeszkadza, ale przy bardzo ciężkich przekrojach, dużych wolumenach i wielu jednoczesnych użytkownikach trzeba uważać. Wtedy same tabele mogą już nie wystarczyć i sensownie jest dołożyć warstwę raportową, hurtownię danych albo przynajmniej dobrze zaprojektowane widoki i indeksy.
| Sytuacja | Model relacyjny | Kiedy rozważyć inne podejście |
|---|---|---|
| System zamówień, płatności, faktur | Bardzo dobry wybór | Rzadko, chyba że schemat jest skrajnie zmienny |
| Raporty wielotabelowe i kontrola jakości | Naturalne środowisko pracy | Zwykle nie ma potrzeby zmiany modelu |
| Dane półstrukturalne, często zmieniający się format | Da się, ale bywa niewygodnie | Gdy schemat ewoluuje bardzo szybko, lepszy bywa model dokumentowy |
| Bardzo duża skala odczytów prostych kluczy | Działa, lecz wymaga strojenia | Przy ekstremalnej skali sens mają rozwiązania NoSQL lub hybrydowe |
| Hurtownia danych do analiz przekrojowych | Może być bazą źródłową | Warstwę analityczną często buduje się osobno, np. w schemacie gwiazdy |
Nie chodzi więc o to, by wybierać jeden model „na zawsze”, tylko o to, by dobrać go do sposobu pracy z danymi. Jeśli dane mają wspierać decyzje i rozliczenia, relacyjny porządek zwykle daje większą przewidywalność niż elastyczność za wszelką cenę.
Jak projektuję bazę pod analitykę, żeby nie zablokować wydajności
Gdy baza ma służyć nie tylko do zapisu, ale też do raportów, zaczynam od bardzo praktycznego pytania: które zapytania będą wykonywane najczęściej i które z nich muszą być szybkie? To od razu ustawia priorytety. Nie projektuję tabel pod abstrakcyjny ideał, tylko pod realne użycie. W analizie danych to zwykle oznacza połączenie porządnej normalizacji z kilkoma świadomymi uproszczeniami po stronie odczytu.
- Zacznij od jednoznacznych encji - osobne tabele dla klientów, zamówień, płatności i produktów pozwalają uniknąć powielania danych.
- Normalizuj to, co często się powtarza - słowniki, statusy, kategorie i dane referencyjne warto trzymać osobno, żeby ograniczyć błędy.
- Nie rozbijaj wszystkiego bez potrzeby - zbyt wiele małych tabel może utrudnić raporty i zwiększyć liczbę joinów.
- Dodaj indeksy tam, gdzie filtrujesz i łączysz najczęściej - bez tego nawet dobra struktura może działać wolno.
- Oddziel obciążenie operacyjne od analitycznego - jeśli raporty są ciężkie, lepiej ich nie uruchamiać bezpośrednio na głównej bazie transakcyjnej.
- Sprawdzaj plan zapytań - czasem jeden zły join kosztuje więcej niż cała reszta modelu razem wzięta.
W wielu projektach sprawdza się też podejście warstwowe. Warstwa operacyjna dba o zapis i integralność, a warstwa analityczna o wygodne odczyty, agregacje i dashboardy. Dzięki temu użytkownik biznesowy nie musi znać wszystkich niuansów struktury tabel, a zespół techniczny nie jest zmuszony do ciągłego gaszenia pożarów wydajnościowych. Taki podział prowadzi do jednego z najczęstszych problemów, które widzę w praktyce.
Najczęstsze błędy, które psują jakość danych i czas odpowiedzi
Najwięcej kłopotów nie bierze się z samego modelu relacyjnego, tylko z jego złego użycia. Widziałem to wielokrotnie: baza wygląda dobrze na diagramie, ale w praktyce raporty są wolne, a wyniki nie zgadzają się między działami. Zwykle winne są te same schematy błędów.
- Duplikowanie tych samych danych w wielu tabelach - potem jedna zmiana trafia tylko do części rekordów i analizy przestają się zgadzać.
- Brak kluczy i ograniczeń - bez nich baza przyjmuje dane, których nie da się później sensownie zinterpretować.
- Za dużo joinów bez kontroli planu zapytania - złożoność rośnie szybciej, niż wielu osobom się wydaje.
- Trzymanie danych operacyjnych i raportowych w jednym miejscu bez izolacji - raport potrafi wtedy spowolnić cały system.
- Projektowanie pod pojedynczy dashboard, a nie pod cały proces - jedna metryka wychodzi dobrze, ale reszta danych staje się trudna do utrzymania.
- Brak indeksów na kolumnach łączenia - to jeden z najprostszych powodów, dla których „niby działa, ale wolno”.
Jeśli miałbym wskazać jedną zasadę obronną, powiedziałbym tak: każdy rekord powinien mieć jasne miejsce w systemie i jedno źródło prawdy. To brzmi banalnie, ale właśnie ta zasada odróżnia dobrze utrzymaną bazę od zbioru tabel, które z czasem zaczynają żyć własnym życiem.
Jak wykorzystać ten model, żeby raporty były naprawdę użyteczne
Najbardziej praktyczny wniosek jest prosty: wybór modelu relacyjnego ma sens wtedy, gdy dane mają pracować na decyzje, a nie tylko na przechowywanie. W takim układzie tabelowy porządek, relacje między encjami i SQL tworzą solidną bazę do raportów, kontroli jakości i automatyzacji. Nie potrzebujesz przy tym przesadnej komplikacji. Często najlepszy efekt daje dobrze zaprojektowana struktura, kilka sensownych indeksów i jasne rozdzielenie obszaru operacyjnego od analitycznego.
Jeśli projekt ma rosnąć, myślę o nim jak o systemie, który będzie czytany częściej niż pisany. To zmienia perspektywę. Zamiast pytać tylko o to, jak zapisać dane, zaczynam pytać, jak szybko i bezbłędnie będzie można je połączyć, zgrupować i porównać. Właśnie wtedy relacyjny model pokazuje swoją największą wartość: nie jako teoria o tabelach, ale jako praktyczny sposób na wiarygodną analizę.
Jeśli chcesz, kolejnym krokiem powinno być sprawdzenie, które zapytania w Twoim systemie są najczęstsze i czy obecna struktura naprawdę je wspiera, bo to właśnie tam zwykle wychodzi różnica między poprawną bazą a bazą, która faktycznie pomaga pracować z danymi.