Surowe pliki z systemów sprzedaży, aplikacji, logów i sensorów mają dużą wartość, ale tylko wtedy, gdy można je później sensownie połączyć i przeanalizować. Właśnie dlatego architektura data lake jest tak ważna w analizie danych: pozwala trzymać informacje w natywnej postaci, nie zamykając sobie drogi do przyszłych zastosowań. W tym artykule pokazuję, jak działa taka warstwa, kiedy ma przewagę nad klasycznym magazynem danych i gdzie najczęściej pojawiają się błędy wdrożeniowe.
Najważniejsze rzeczy, które warto wiedzieć przed wdrożeniem
- Największa siła tego podejścia polega na przechowywaniu danych w surowej postaci, bez wymuszania jednego schematu na starcie.
- Najlepiej sprawdza się tam, gdzie źródeł jest dużo, formaty są różne, a pytania analityczne dopiero się wyłaniają.
- Sama przestrzeń dyskowa nie wystarczy. Potrzebne są metadane, katalog danych, zasady jakości i kontrola dostępu.
- Bez porządku warstwy szybko zamieniają się w składowisko plików, z którego trudno korzystać.
- W wielu organizacjach to rozwiązanie dobrze współgra z lakehouse, jeśli obok eksploracji potrzebne jest też stabilne BI.
Czym jest jezioro danych i kiedy naprawdę się przydaje
Ja patrzę na to tak: jeśli jeszcze nie wiesz, jakie pytania biznesowe pojawią się za pół roku, potrzebujesz miejsca, które przechowa dane bez ich uprzedniego spłaszczania do jednego schematu. Taka architektura daje swobodę pracy z danymi strukturalnymi, półstrukturalnymi i nieustrukturalnymi: od tabel transakcyjnych po JSON-y, logi, obrazy czy nagrania. Jej wartość zaczyna się tam, gdzie klasyczny magazyn danych okazuje się zbyt sztywny, a rozproszone pliki przestają być zarządzalne.
Nie chodzi jednak o prosty skład plików. Dobrze zorganizowane jezioro danych przechowuje dane surowe, ale jednocześnie utrzymuje porządek metadanych, uprawnień i historii pochodzenia. To właśnie ta różnica decyduje, czy zbiory danych staną się paliwem do analizy, czy chaotycznym archiwum, z którego nikt nie chce korzystać.
Najważniejsza zasada brzmi: najpierw zapisujesz dane, a dopiero potem decydujesz, jak je interpretować podczas odczytu. To daje elastyczność, ale przerzuca większą odpowiedzialność na katalog, jakość i governance. Gdy już wiesz, do czego służy taka warstwa, sensownie jest zobaczyć, z jakich elementów składa się od środka.
Jak działa architektura od surowych plików do analizy
W praktyce dobrze działające środowisko ma zwykle trzy warstwy. Ja lubię ten układ, bo oddziela przechowywanie od porządkowania i od warstwy, którą rzeczywiście dotyka analityka.
Strefa surowa
Tu trafiają dane dokładnie takie, jakie przyszły z systemu źródłowego. Zachowuję oryginał, bo przy późniejszej analizie często wraca pytanie o kontekst: kiedy rekord powstał, z którego źródła przyszedł i w jakiej wersji schematu. W praktyce to warstwa do przechowywania, nie do ręcznego poprawiania.
Strefa przetworzona
Na tym etapie normalizuję formaty, usuwam duplikaty, waliduję typy i dzielę dane na sensowne partycje, najczęściej po dacie, domenie lub źródle. Dzięki temu analitycy nie muszą za każdym razem robić tej samej pracy od zera. To też moment, w którym warto ustalić reguły jakości, bo błędy zasilania wchodzą tu najtaniej do naprawienia.
Przeczytaj również: Mechanika i budowa maszyn: najlepsze ścieżki kariery po studiach
Warstwa prezentacyjna
To miejsce, z którego korzysta BI, analityka operacyjna i modele ML. Dane są już opisane, lepiej nazwane i łatwiejsze do odczytu. W dobrze prowadzonym projekcie ta warstwa nie zastępuje surowych plików, tylko z nich korzysta, dzięki czemu zespół nie traci kontekstu historycznego.
Do tego dochodzi katalog metadanych: właściciel danych, opis pól, źródło, czas odświeżenia, reguły dostępu i lineage, czyli ścieżka pochodzenia rekordu. Bez tego trudno mówić o poważnej analityce, bo sam storage nie odpowiada na pytanie, skąd wzięła się dana liczba. Taki układ prowadzi naturalnie do porównania z innymi podejściami.
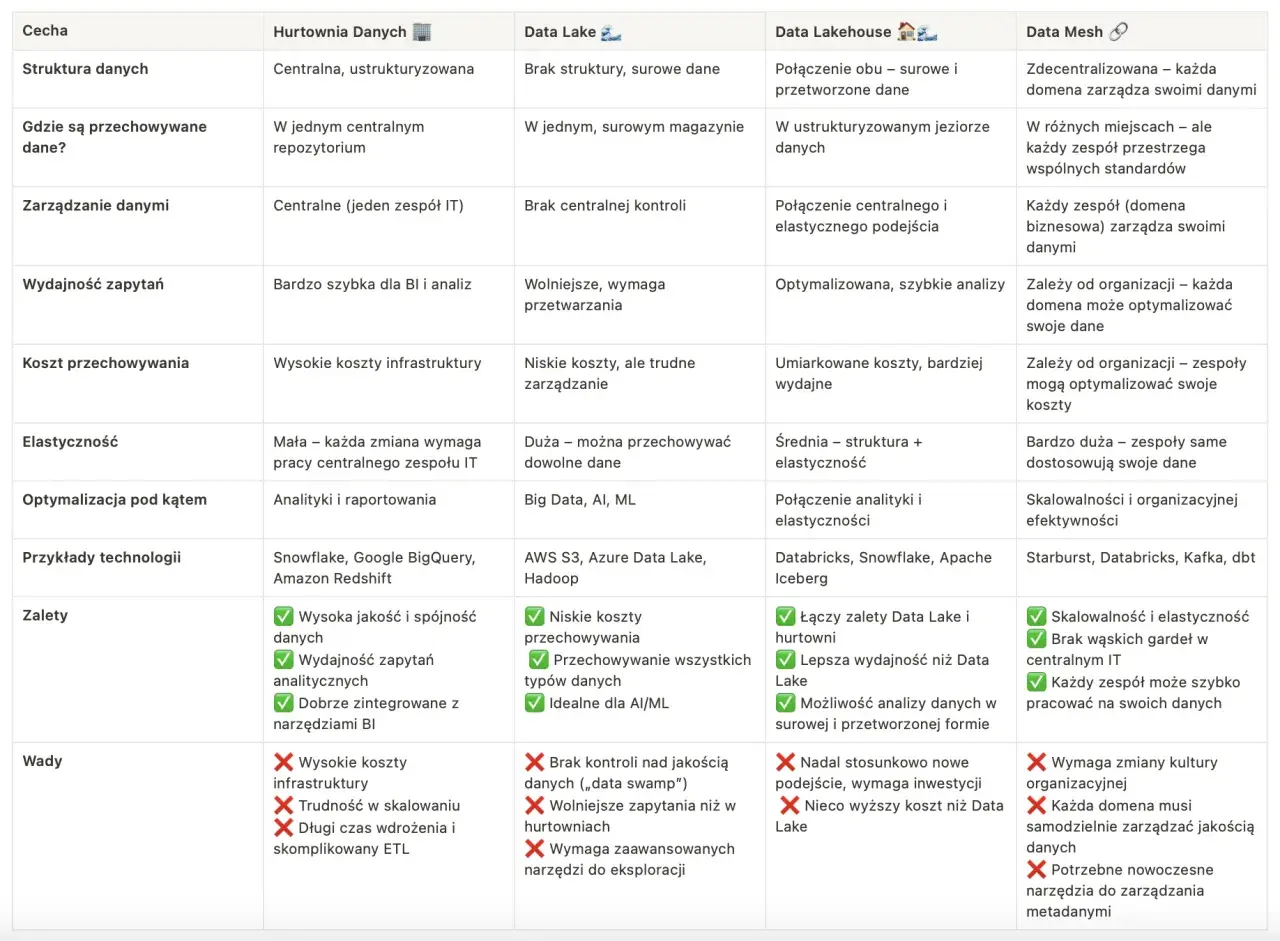
Jezioro danych, magazyn danych i lakehouse nie są tym samym
Największe nieporozumienie polega na tym, że te trzy podejścia traktuje się jak zamienne etykiety. W praktyce każde rozwiązuje inny problem i inaczej kosztuje organizację.
| Cecha | Jezioro danych | Magazyn danych | Lakehouse |
|---|---|---|---|
| Typ danych | Strukturalne, półstrukturalne i nieustrukturalne | Głównie strukturalne | Strukturalne, półstrukturalne i nieustrukturalne |
| Podejście do schematu | Schema-on-read | Schema-on-write | Hybryda z kontrolą metadanych |
| Główne użycie | Eksploracja, ML, logi, AI | Raporty, KPI, BI | BI, analityka eksploracyjna i AI |
| Siła | Elastyczność i skala | Porządek i szybkość zapytań | Łączy elastyczność z lepszym ładem |
| Ryzyko | Chaos bez governance | Mniejsza elastyczność | Większa złożoność niż prosty magazyn |
Jeśli potrzebujesz stabilnych raportów zarządczych, magazyn danych nadal bywa prostszym wyborem. Jeśli chcesz łączyć raportowanie z eksperymentami, lakehouse często daje lepszy kompromis. Jezioro danych pozostaje najmocniejsze tam, gdzie ważniejsza jest pełna historia danych niż natychmiastowa gotowość do raportu. A skoro wybór zależy od procesu, kolejnym krokiem jest rozsądne zaprojektowanie wdrożenia.
Jak zbudować je bez chaosu
Ja zwykle zaczynam od procesu, nie od narzędzia. Najpierw trzeba odpowiedzieć, kto będzie korzystał z danych, jak często, do jakich decyzji i które źródła są krytyczne. Dopiero potem ma sens wybór konkretnej platformy.
- Wypisz źródła i częstotliwość zasilania. Inaczej projektuje się system dzienny, inaczej streaming co kilka sekund.
- Ustal trzy warstwy danych: surową, przetworzoną i prezentacyjną.
- Dodaj katalog metadanych oraz właściciela każdego zbioru. Bez właściciela dane szybko tracą wiarygodność.
- Wprowadź walidację jakości przy wejściu: typy, kompletność, duplikaty i zakresy wartości.
- Zdefiniuj politykę dostępu i retencji. Nie każdemu trzeba dawać wgląd do wszystkiego.
- Ustal, które raporty i modele będą budowane na danych pośrednich, a które bezpośrednio na surowych plikach.
Przy dużych wolumenach warto też przechodzić na formaty kolumnowe i sensowne partycjonowanie, bo to realnie obniża koszty odczytu oraz przyspiesza analitykę. Z mojego doświadczenia największą różnicę robi nie samo narzędzie, ale konsekwentne nadawanie nazw, wersji i właścicieli. Kiedy tego brakuje, nawet dobrze zaprojektowana technologia zaczyna się rozjeżdżać.
Najczęstsze błędy, które zamieniają projekt w składowisko plików
Widziałem już projekty, które po kilku miesiącach zamieniały się w kosztowne archiwum, bo na starcie zabrakło kilku zasad. Najczęściej problem nie polega na złej technologii, tylko na zbyt luźnym podejściu do ładu danych.
- Ładowanie wszystkiego bez celu. Jeśli nie wiesz, do jakiej decyzji dana tabela ma służyć, rośnie tylko koszt przechowywania i chaos.
- Brak katalogu. Bez opisu pól, źródeł i właściciela analityk nie ufa danym.
- Mieszanie warstw. Gdy surowe pliki, gotowe zestawienia i robocze transformacje lądują w jednym miejscu, nikt nie wie, co jest wersją referencyjną.
- Pomijanie jakości. Brak walidacji na wejściu oznacza, że błędy z systemu źródłowego rozleją się na cały ekosystem.
- Zbyt szerokie uprawnienia. Dane wrażliwe powinny być odseparowane, a dostęp nadawany po potrzebie, nie na wszelki wypadek.
- Brak właściciela biznesowego. Technologia może działać, ale bez odpowiedzialności nikt nie pilnuje użyteczności danych.
Najczęstszy symptom problemu jest prosty: zespół pyta o te same pliki kilka razy i za każdym razem dostaje inną odpowiedź. To znak, że pora wrócić do warstw, metadanych i zasad dostępu. Gdy ten porządek jest ustalony, można ocenić, kiedy takie podejście rzeczywiście daje przewagę.
Kiedy ta architektura daje przewagę w analizie danych
Ta architektura ma największy sens tam, gdzie dane są różnorodne, a pytania jeszcze nie są w pełni zdefiniowane. Dobrze sprawdza się w logach aplikacyjnych, clickstreamie, danych z IoT, integracji wielu systemów, analityce zachowań użytkowników i projektach uczenia maszynowego.
Przykład jest prosty: jeśli chcesz analizować ścieżki klientów w sklepie internetowym, sam zestaw zamówień nie wystarczy. Potrzebujesz też zdarzeń z aplikacji, kampanii marketingowych, zwrotów, opóźnień dostaw i ewentualnie danych z obsługi klienta. Surowa warstwa pozwala zachować pełen kontekst, a to często robi różnicę między ciekawym wykresem a naprawdę użytecznym wnioskiem.
Są jednak sytuacje, w których taka architektura nie daje przewagi. Jeśli firma potrzebuje głównie kilku stabilnych raportów finansowych, a struktura danych jest dobrze znana od lat, prostszy magazyn danych może być tańszy i szybszy we wdrożeniu. Ja traktuję to rozwiązanie jako wybór dla organizacji, które chcą rozwijać analitykę, a nie tylko odtwarzać stałe raporty. To prowadzi do prostego, ale ważnego pytania: co trzeba sprawdzić, zanim zacznie się wdrożenie?
Co sprawdzić przed pierwszym wdrożeniem
Przed uruchomieniem tego typu środowiska sprawdzam pięć rzeczy: czy wiem, jakie dane mają być przechowywane w surowej postaci, czy mam katalog metadanych, czy każda domena ma właściciela, czy polityka dostępu jest jasna oraz czy z góry rozdzielam warstwę analityczną od surowej. Jeśli na któreś z tych pytań odpowiadam niepewnie, problemem nie jest technologia, tylko brak projektu.
- Czy dane surowe mają sens biznesowy, czy trafiają do repozytorium na zapas?
- Czy znam źródła, częstotliwość zasilania i formaty plików?
- Czy istnieje katalog metadanych i właściciel każdego zbioru?
- Czy wiadomo, które dane są wrażliwe i kto ma do nich dostęp?
- Czy potrafię wskazać, która warstwa zasila raporty, a która eksperymenty?
Jeśli te odpowiedzi są jasne, wdrożenie ma szansę stać się narzędziem do realnej analizy, a nie kolejnym kosztownym miejscem składowania plików. I właśnie wtedy surowe dane zaczynają pracować na decyzje, zamiast tylko zajmować przestrzeń.