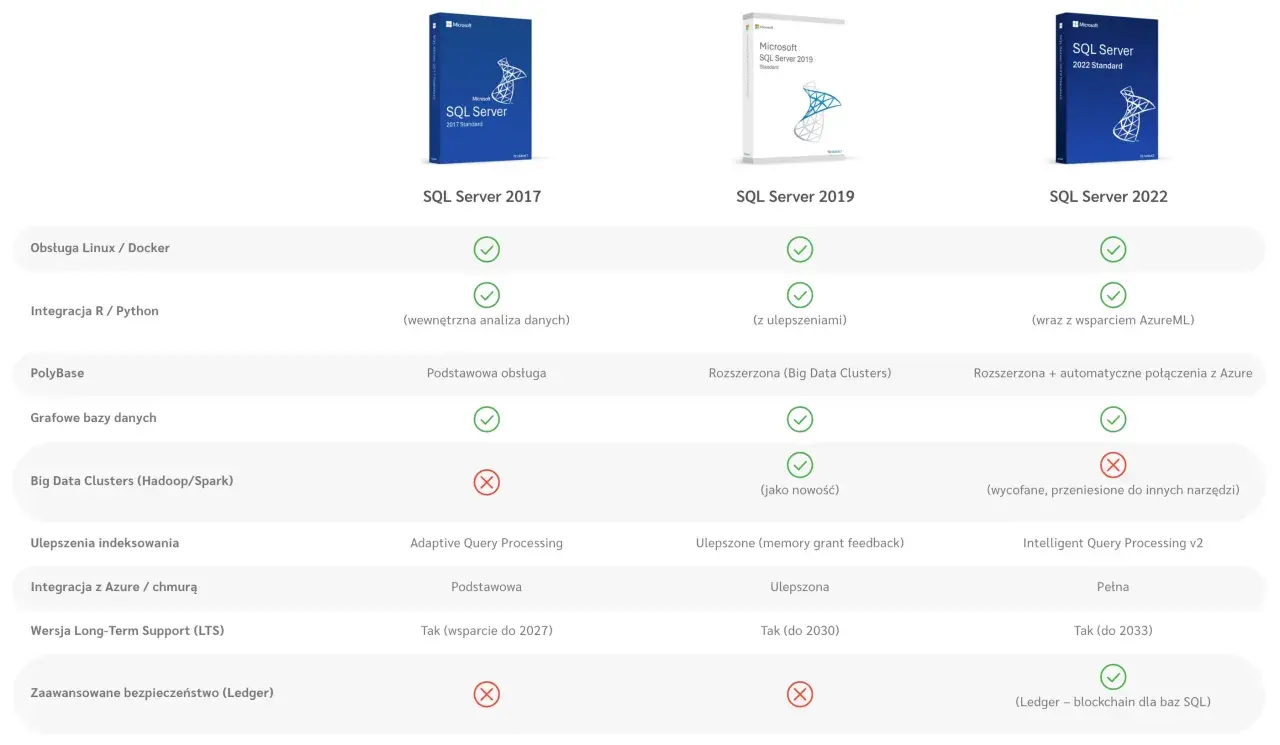
SQL Server 2022 to dobry punkt wyjścia, jeśli chcesz połączyć stabilną bazę relacyjną z sensowną analizą danych bez budowania wszystkiego od zera. W praktyce to wydanie pomaga zarówno przy raportach operacyjnych, jak i przy scenariuszach hybrydowych, gdzie część danych zostaje lokalnie, a część trafia do chmury lub warstwy analitycznej. Poniżej pokazuję, co naprawdę działa, kiedy ta wersja ma przewagę i gdzie jej możliwości kończą się szybciej, niż wielu osobom się wydaje.
Najważniejsze rzeczy, które warto wiedzieć przed wdrożeniem
- To nadal przede wszystkim relacyjny silnik bazodanowy, ale z mocnym naciskiem na scenariusze analityczne i hybrydowe.
- Query Store, inteligentne przetwarzanie zapytań i analiza near real-time robią tu większą różnicę niż pojedyncze „efekciarskie” nowości.
- W analizie danych duże znaczenie ma poziom zgodności bazy, bo część usprawnień wymaga ustawień na poziomie 160.
- Nie zastępuje automatycznie hurtowni danych, ale potrafi ją odciążyć albo opóźnić moment, w którym trzeba ją zbudować.
- W 2026 to nadal bezpieczny wybór planistyczny: mainstream support kończy się 11 stycznia 2028, a extended support 11 stycznia 2033.
Dlaczego ta wersja ma znaczenie w analizie danych
Najważniejsza rzecz, którą chcę tu podkreślić, jest prosta: ta platforma nie udaje osobnej hurtowni danych, ale daje solidną bazę do analityki tam, gdzie dane operacyjne i raportowanie muszą żyć obok siebie. To szczególnie ważne w firmach, które mają jeden system sprzedażowy, jeden CRM albo jedną aplikację wewnętrzną i nie chcą od razu rozbudowywać architektury o kilka kolejnych warstw.
W praktyce widzę to tak: jeśli masz OLTP, czyli bazę obsługującą bieżące transakcje, to każda cięższa analiza może ją spowalniać. Nowsze wydanie SQL Servera pomaga ograniczyć ten konflikt, bo oferuje lepsze planowanie zapytań, wygodniejsze monitorowanie wydajności i mosty do środowisk chmurowych. To nie jest drobna kosmetyka, tylko realna zmiana podejścia do pracy z danymi.
W 2026 dochodzi jeszcze argument cyklu życia produktu. To nie jest rozwiązanie „na chwilę”: wsparcie mainstream trwa do 11 stycznia 2028, a extended support do 11 stycznia 2033. Dla projektu analitycznego to bardzo praktyczna informacja, bo inwestycja w model danych, indeksy, procesy ETL i raporty zwykle zwraca się przez lata, a nie przez kilka miesięcy. Z tego punktu przechodzę już do rzeczy, które faktycznie dają przewagę w codziennej pracy.
Funkcje, które naprawdę pomagają w pracy analitycznej
Nie każda nowość ma znaczenie dla analityka, ale kilka elementów robi różnicę od pierwszego dnia. Najbardziej cenię te funkcje, które zmniejszają liczbę ręcznych poprawek, przyspieszają diagnozowanie problemów i pozwalają pracować bliżej źródła danych, zamiast kopiować wszystko do kolejnych systemów.
| Funkcja | Co daje w praktyce | Kiedy ma największy sens |
|---|---|---|
| Azure Synapse Link for SQL | Pozwala uruchamiać analizę niemal w czasie rzeczywistym na danych operacyjnych przy minimalnym wpływie na bazę źródłową. | Gdy raporty mają być świeże, ale nie chcesz dusić systemu transakcyjnego. |
| Query Store | Zapisuje historię planów wykonania i zachowania zapytań, więc łatwiej wykryć regresję po zmianie indeksu, aktualizacji lub zmianie danych. | Gdy masz powtarzalne raporty i chcesz wiedzieć, dlaczego „nagle” zaczęły działać wolniej. |
| Intelligent Query Processing | Automatycznie poprawia zachowanie wielu zapytań bez ręcznego przepisywania całego kodu. | Gdy masz mieszane obciążenia i nie chcesz optymalizować wszystkiego ręcznie. |
| Cardinality estimation feedback | Lepiej szacuje liczbę wierszy dla powtarzalnych zapytań, co poprawia jakość planów. | Gdy masz raporty złożone z tych samych filtrów, agregacji i joinów. |
| Approximate percentile | Szybko liczy percentyle na dużych zbiorach, gdy wystarczy wynik przybliżony. | Gdy budujesz dashboardy i liczy się szybkość reakcji, a nie wynik co do ostatniej cyfry. |
| Data Lake Virtualization | Pozwala czytać pliki Parquet i dane z zewnętrznych źródeł przez T-SQL. | Gdy część danych już leży w lake'u i chcesz je analizować bez natychmiastowego ładowania wszystkiego do środka. |
Najważniejszy wniosek jest taki, że ta wersja najlepiej działa tam, gdzie analiza danych wyrasta z realnego systemu operacyjnego. Jeśli natomiast ktoś oczekuje pełnej platformy typu „wrzucam wszystko do jednego miejsca i mam od ręki lakehouse”, to będzie rozczarowany. Te mechanizmy pomagają, ale nie zdejmują z zespołu obowiązku dobrego modelowania i kontroli jakości danych. I właśnie dlatego warto spojrzeć na wdrożenie krok po kroku.
Jak zbudować praktyczny scenariusz analityczny krok po kroku
Gdybym dziś projektowała takie środowisko od zera, zaczęłabym od jednego pytania: czy analiza ma działać obok transakcji, czy ponad nimi? To rozróżnienie decyduje o wszystkim, bo inny będzie układ indeksów, inna częstotliwość odświeżania danych i inne miejsce dla raportów. Bez tej decyzji projekt bardzo łatwo zamienia się w zbiór doraźnych obejść.
- Oddziel zapytania operacyjne od analitycznych. Jeśli raport ma skanować duże zakresy danych w godzinach szczytu, nie powinien wisieć bezpośrednio na tej samej ścieżce co sprzedaż, logowanie lub rejestracja zdarzeń.
- Włącz Query Store od początku. To daje mi punkt odniesienia, dzięki któremu widzę, czy zmiana indeksu, planu albo aktualizacji rzeczywiście pomogła. Bez baseline'u optymalizacja jest zgadywaniem.
- Sprawdź poziom zgodności bazy. Część usprawnień związanych z inteligentnym przetwarzaniem zapytań zaczyna pracować dopiero przy odpowiednim ustawieniu, więc nie testowałbym tego „na oko” w produkcji.
- Ustal, które metryki mogą być przybliżone. Dla dashboardu zarządczego procentyl albo agregat przybliżony bywa wystarczający, ale dla rozliczeń finansowych już nie. To brzmi banalnie, a i tak jest częstym źródłem nieporozumień.
- Jeśli potrzebujesz świeżych danych niemal na żywo, użyj Synapse Link albo warstwy lake zamiast ciągnąć ciężkie analizy z bazy transakcyjnej. Tak zwykle oszczędza się najwięcej nerwów i najwięcej CPU.
- Zweryfikuj narzędzia klienckie i sterowniki. Nowsza wersja SSMS i aktualne sterowniki ODBC/OLE DB to nie detal, tylko warunek stabilnego środowiska. Stare komponenty potrafią zepsuć całą przyjemność z migracji.
W tym miejscu wielu osobom wychodzi na jaw, że największy problem nie leży w samym silniku, tylko w braku spójnego modelu pracy z danymi. Jeśli od początku ustawisz sensowną granicę między operacją a analizą, nowsza wersja SQL Servera zaczyna pracować na twoją korzyść, a nie odwrotnie. Następny krok to decyzja, kiedy ta architektura rzeczywiście wygrywa z innymi opcjami.
Kiedy wybrać ją zamiast osobnej hurtowni albo samej chmury
Nie traktowałbym tej wersji jako odpowiedzi na każdy scenariusz analityczny. Bardziej widzę ją jako dobre rozwiązanie pośrednie albo jako fundament, który można rozbudować później. To ważne, bo wiele projektów przegrywa nie przez brak mocy obliczeniowej, tylko przez źle dobrany poziom złożoności na starcie.
| Scenariusz | Co zwykle sprawdza się najlepiej | Dlaczego |
|---|---|---|
| Jedna aplikacja biznesowa i kilka raportów zarządczych | Ta wersja jako główny silnik z dobrze zaprojektowanym raportowaniem | Masz mniej elementów do utrzymania i krótszą drogę od danych do wyniku. |
| Dużo źródeł, wiele transformacji i ciężka analityka historyczna | Osobna hurtownia albo lakehouse | Łatwiej skalować model, ETL i governance, gdy analityka żyje własnym życiem. |
| Środowisko hybrydowe, część danych lokalnie, część w chmurze | Nowsza wersja SQL Servera z Synapse Link i integracją z magazynem obiektowym | Możesz przechodzić do chmury etapami, bez twardego cięcia całej architektury. |
| Użytkownicy oczekują głównie dashboardów, trendów i agregatów | Warstwa analityczna zaprojektowana pod odczyt | Baza transakcyjna nie powinna dźwigać wszystkiego, jeśli analiza jest głównym zadaniem. |
Mój praktyczny skrót jest taki: jeśli jesteś blisko źródła danych i chcesz szybko dać biznesowi sensowny raport, ta platforma jest bardzo rozsądna. Jeśli natomiast analityka ma obsługiwać wiele domen, wiele zespołów i ciężkie przetwarzanie historyczne, lepiej od razu myśleć szerzej. To nie jest wada produktu, tylko zwykły realizm architektoniczny. Z tego samego powodu trzeba też znać pułapki.
Najczęstsze błędy, które psują wdrożenie
Najgorszy błąd, jaki widzę, to próba zrobienia z bazy transakcyjnej „wszystkiego naraz”. Wtedy raporty walczą z zapisami, indeksy są dokładane reaktywnie, a każdy spadek wydajności urasta do problemu systemowego. Da się to uratować, ale kosztuje to zwykle więcej niż porządne zaplanowanie architektury na początku.
- Brak rozdzielenia obciążeń - ciężkie raporty trafiają bezpośrednio na ten sam silnik, który obsługuje bieżące operacje.
- Oczekiwanie, że Synapse Link załatwi model danych - narzędzie pomaga w przepływie danych, ale nie zastępuje logiki biznesowej ani czyszczenia danych.
- Ignorowanie poziomu zgodności - część usprawnień IQP nie daje pełnego efektu, jeśli nie ustawisz właściwej kompatybilności bazy.
- Mylenie wyników przybliżonych z dokładnymi - approximate percentile jest świetny do trendów, ale nie do rozliczeń.
- Praca na starych komponentach - do nowych wdrożeń lepiej używać aktualnych sterowników i nowszych narzędzi administracyjnych.
- Brak planu utrzymania - baza analityczna bez monitoringu Query Store i bez kontroli zmian po aktualizacjach szybko traci przewagę.
Warto też pamiętać o jednym technicznym detalu: w tej wersji nie instalują się już domyślnie środowiska R, Python i Java dla usług Machine Learning Services. Jeśli ktoś liczy na gotowe analityczne runtime'y „z pudełka”, może się zdziwić. Ja traktuję to jako sygnał, że trzeba świadomie zaprojektować warstwę obliczeniową, zamiast zakładać, że wszystko pojawi się automatycznie. I tu dochodzimy do najpraktyczniejszej części całego tematu.
Jak wycisnąć z niego maksimum bez chaosu w architekturze
Gdybym miała zamknąć ten temat w kilku zasadach operacyjnych, powiedziałabym tak: nie zaczynaj od funkcji, tylko od przepływu danych. Najpierw ustal, skąd dane przychodzą, jak często mają się odświeżać, które raporty muszą być dokładne, a które mogą być szybkie i przybliżone. Dopiero potem dobieraj mechanizmy.
- Trzymaj jedną, jasno opisaną warstwę źródłową i jedną warstwę analityczną, nawet jeśli obie działają w tym samym ekosystemie.
- Monitoruj Query Store od pierwszego dnia, bo to najprostszy sposób na wykrycie regresji po zmianach.
- W testach sprawdzaj wpływ poziomu zgodności bazy na konkretne zapytania, a nie tylko na ogólny benchmark.
- Jeśli używasz przybliżeń, nazwij to wprost w modelu danych i raportach, żeby nikt nie mylił „szybciej” z „dokładniej”.
- Planuj aktualizacje i sterowniki razem z bazą, bo w analityce drobne różnice wersji potrafią wywołać nieproporcjonalnie duże problemy.
W mojej ocenie ta platforma jest najmocniejsza tam, gdzie ma łączyć stabilność relacyjnej bazy z rozsądną analityką, a nie udawać pełne środowisko lakehouse. Jeśli potraktujesz ją właśnie tak, zyskasz narzędzie, które daje dużo elastyczności, nie wymuszając od razu wielkiej i kosztownej przebudowy całego stosu danych. To zwykle najlepszy kompromis między szybkością wdrożenia, kontrolą i przyszłą skalowalnością.