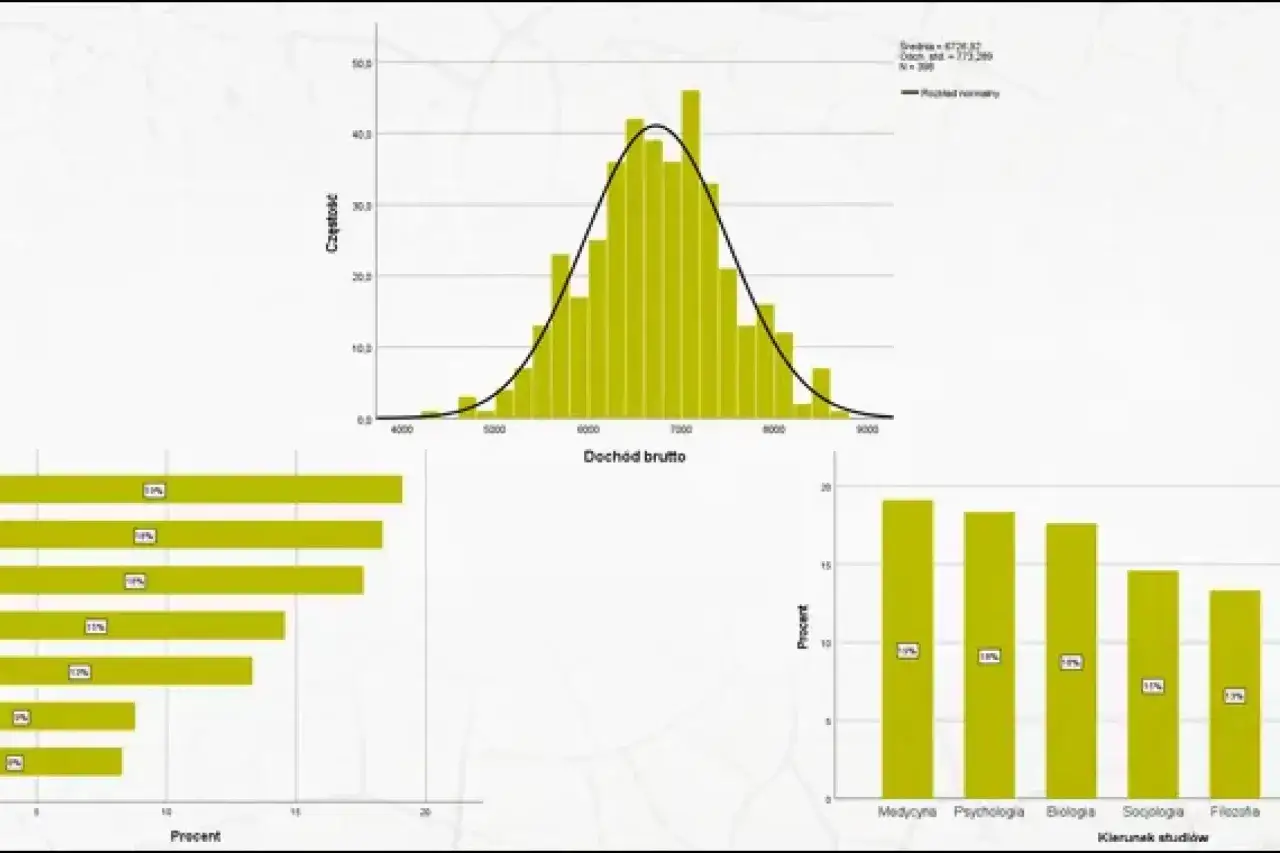
Histogram to prosty, ale bardzo pożyteczny sposób pokazania, jak rozkładają się wartości liczbowe w zbiorze danych. Gdy pracuję z wynikami testów, czasem nauki albo pomiarami sprzedaży, ten jeden wykres często mówi więcej niż sama średnia, bo od razu widać skupienia, ogony i wartości odstające. W tym tekście pokazuję, jak go czytać, jak go zbudować i jak uniknąć wniosków, które wyglądają dobrze tylko na pierwszy rzut oka.
Najpierw sprawdź kształt rozkładu, a dopiero potem wyciągaj wnioski
- Najważniejsze są: środek danych, rozrzut, skośność i odstające wartości.
- Ten sam zbiór liczb może wyglądać inaczej po zmianie szerokości przedziałów.
- Do danych liczbowych używa się innego wykresu niż do kategorii.
- Przy porównaniach grup różnej wielkości lepiej patrzeć na procenty niż na surowe liczby.
- W edukacji i rozwoju osobistym ten wykres pomaga ocenić powtarzalność wyników, a nie tylko ich poziom.
Jak czytać histogram w praktyce
Najpierw patrzę na trzy rzeczy: gdzie jest najwyższy obszar, czy po obu stronach rozkład zachowuje równowagę i czy któreś wartości nie odklejają się od reszty. Jak opisuje NIST, taki wykres pozwala szybko ocenić środek danych, ich rozrzut, skośność, obecność odstających obserwacji i to, czy pojawia się więcej niż jeden wyraźny szczyt. To właśnie dlatego bywa pierwszym krokiem, zanim sięgnę po bardziej szczegółowe statystyki.
| Co widzisz | Co to zwykle znaczy | Na co uważać |
|---|---|---|
| Jeden wyraźny szczyt | Dane skupiają się wokół jednej typowej wartości | Sprawdź, czy to nie efekt zbyt szerokich przedziałów |
| Długi ogon po prawej stronie | Większość wartości jest niższa, a kilka mocno podbija zakres | Średnia może wyglądać lepiej lub gorzej niż typowy wynik |
| Długi ogon po lewej stronie | Większość wartości jest wyższa, a kilka mocno zaniża obraz | Nie myl pojedynczych niskich obserwacji z normalnym poziomem całej grupy |
| Dwa wyraźne szczyty | W danych mogą mieszać się dwie różne grupy lub dwa procesy | Nie traktuj ich od razu jako jednej całości |
| Pojedynczy słupek na skraju | Możliwy błąd pomiaru, wyjątkowy przypadek albo realny outlier | Najpierw sprawdź kontekst, dopiero potem decyduj, co z tym zrobić |
W praktyce najszybciej zadaję sobie pytanie: czy ten wykres opisuje jedną spójną grupę, czy kilka różnych zachowań naraz? Jeśli odpowiedź nie jest oczywista, już mam sygnał, że trzeba spojrzeć głębiej. Z takim obrazem łatwiej przejść do budowania własnego wykresu.
Jak zbudować taki wykres z własnych danych
Najprościej myśleć o tym jak o podziale osi liczbowej na koszyki. Do każdego koszyka trafia liczba obserwacji, a wysokość słupka pokazuje, ile ich tam wpadło. Im większy koszyk, tym gładszy obraz; im mniejszy, tym więcej detalu i jednocześnie więcej szumu.
- Wybierz jedną zmienną liczbową. Czas nauki, wynik testu, liczba kroków albo koszt zadania to dobre przykłady, ale nie mieszaj kilku różnych rzeczy naraz.
- Sprawdź dane wejściowe. Braki, literówki i nierealne wartości potrafią zepsuć cały obraz szybciej, niż się wydaje.
- Podziel zakres na przedziały o równej szerokości. Przy małej próbie nie przesadzaj z liczbą klas, bo wykres zacznie wyglądać jak przypadkowy szum.
- Policz, ile obserwacji wpada do każdego przedziału. Gdy porównujesz grupy różnej wielkości, lepiej patrzeć na procenty niż tylko na liczebności.
- Sprawdź kilka wariantów podziału. Jeśli drobna zmiana całkowicie odwraca wniosek, to znak, że wykres jest zbyt niestabilny.
W praktyce często robię dwa albo trzy warianty i wybieram ten, który pokazuje strukturę danych bez sztucznego podkręcania efektu. Dzięki temu łatwiej odróżnić realny wzorzec od przypadkowego układu słupków. A skoro już wiesz, jak taki wykres powstaje, czas wyjaśnić najczęstsze pomyłki przy jego czytaniu.
Dlaczego to nie to samo co wykres słupkowy
To jedna z najczęstszych pułapek: na pierwszy rzut oka oba wykresy wyglądają podobnie, ale służą do zupełnie innych rzeczy. Jeden pokazuje rozkład liczb, drugi porównuje kategorie. Jeśli pomylisz te dwa narzędzia, możesz wyciągnąć wnioski, które technicznie wyglądają poprawnie, ale znaczą coś zupełnie innego.
| Kryterium | Wykres rozkładu | Wykres słupkowy |
|---|---|---|
| Rodzaj danych | Liczby, zwłaszcza ciągłe lub przedziałowe | Kategorie, grupy lub etykiety |
| Kolejność osi | Kolejność ma znaczenie, bo opiera się na skali liczbowej | Kolejność zwykle można zmieniać |
| Przerwy między słupkami | Zazwyczaj ich nie ma, bo przedziały łączą się ze sobą | Przerwy są naturalne, bo kategorie są oddzielne |
| Główne pytanie | Jak wygląda rozkład wartości? | Która kategoria ma więcej lub mniej? |
| Dobry przykład | Wyniki testu, czas reakcji, wysokość, dochód | Rodzaj kursu, kraj, typ zadania, ulubiona metoda nauki |
Jeśli chcesz porównać kategorie, używaj słupków. Jeśli chcesz zobaczyć kształt rozkładu liczbowego, wybieraj wykres z przedziałami. Ta różnica jest niewielka wizualnie, ale ogromna interpretacyjnie. Gdy już ją masz uporządkowaną, łatwiej zauważyć błędy, które psują analizę.
Najczęstsze błędy przy interpretacji
Tu najczęściej widzę pośpiech. Sam wykres bywa poprawny, ale interpretacja już nie. W praktyce najbardziej szkodzą nie złe narzędzia, tylko zbyt szybkie domykanie wniosku.
- Za mała próba. Dwadzieścia obserwacji nie daje jeszcze stabilnego obrazu rozkładu.
- Dowolne zmienianie szerokości przedziałów aż obraz „pasuje” do tezy.
- Ignorowanie wartości skrajnych, które mogą być błędem albo cennym sygnałem.
- Porównywanie surowych liczebności grup o różnej wielkości zamiast procentów.
- Mylenie jednego szczytu z jednorodnością, choć dane mogą pochodzić z dwóch różnych źródeł.
Ja zwykle najpierw pytam, skąd te liczby pochodzą i czy nie łączę dwóch różnych populacji pod jednym wykresem. Dopiero później zadaję pytanie, co dokładnie oznacza szczyt lub ogon. Ta kolejność oszczędza sporo błędów. A teraz przejdźmy do zastosowań, w których taki wykres daje najwięcej praktycznej wartości.
Gdzie ten wykres daje największą wartość w analizie danych
W pracy z danymi rozwojowymi ten typ wykresu jest szczególnie użyteczny, bo pokazuje nie tylko wynik, ale też powtarzalność zachowań. To ważne, gdy chcesz ocenić postęp, a nie tylko pojedynczy sukces albo pojedynczą wpadkę.
- Wyniki testów i quizów. Od razu widać, czy poprawa dotyczy całej grupy, czy tylko kilku osób, które mocno wybiły się ponad resztę.
- Czas wykonania zadania. Możesz sprawdzić, czy większość osób pracuje w podobnym tempie, czy część potrzebuje wyraźnie więcej czasu.
- Liczba dni z nawykiem w miesiącu. Taki obraz pokazuje, czy rutyna jest stabilna, czy opiera się na krótkich zrywach.
- Skuteczność sesji nauki. Porównasz rozkład czasu skupienia przed i po zmianie metody i zobaczysz, czy nowy sposób faktycznie coś zmienia.
W takich zastosowaniach nie chodzi o efekt „ładnego wykresu”, tylko o to, czy dane pokazują realny wzorzec działania. Gdy widzisz dwa wyraźne skupienia, często oznacza to, że jedna strategia działa dobrze, a druga wyraźnie gorzej, więc warto je rozdzielić. To prowadzi do ostatniej rzeczy, którą zawsze sprawdzam przed wyciągnięciem wniosku.
Zanim zaufasz wykresowi, sprawdź te trzy rzeczy
Na końcu wracam do trzech pytań, które porządkują całą interpretację: czy próbka jest wystarczająca, czy przedziały są ustawione sensownie i czy porównuję właściwy typ danych. Jeśli na któreś z nich odpowiadasz „nie wiem”, to znak, że trzeba jeszcze chwilę popracować nad obrazem danych, zamiast od razu budować na nim decyzję.
- Czy próbka jest reprezentatywna, a nie przypadkowa lub zbyt mała.
- Czy sposób grupowania liczb nie zmienia sztucznie wniosku.
- Czy patrzysz na liczby bezwzględne, czy na procenty, zależnie od celu analizy.
Jeśli te trzy elementy są w porządku, wykres staje się naprawdę użytecznym narzędziem: szybko pokazuje, gdzie jest centrum danych, jak szeroki jest rozrzut i czy w tle nie kryje się coś więcej niż jeden prosty trend. To właśnie dlatego tak chętnie wracam do niego na początku analizy, zanim zacznę budować bardziej złożone modele.