W analizie danych sama średnia rzadko wystarcza, bo nie mówi, czy wyniki są równe i spokojne, czy rozjeżdżają się mocno między sobą. Najprościej pokazuje to odchylenie standardowe, czyli miarę typowej odległości wartości od średniej. W praktyce pozwala mi szybko ocenić spójność danych, porównać dwie grupy i wyłapać sytuacje, w których jeden „ładny” wynik przykrywa duży chaos pod spodem.
Najkrócej mówiąc, ta miara pokazuje, jak bardzo dane uciekają od średniej
- Im niższa wartość, tym obserwacje są bardziej skupione wokół średniej.
- Wynik 0 oznacza, że wszystkie wartości są identyczne.
- Wynik ma tę samą jednostkę co dane, więc łatwo go odczytać bez dodatkowych przeliczeń.
- W próbie zwykle używa się mianownika n-1, a nie samego n.
- Pojedyncze wartości odstające potrafią mocno zawyżyć wynik, dlatego kontekst ma znaczenie.
- Przy porównywaniu różnych skal często lepiej sprawdza się miara względna niż sam rozrzut bezwzględny.
Jak interpretować wynik bez fałszywych wniosków
Ja traktuję tę miarę jak szybki test spójności. Gdy jest mała, obserwacje są blisko siebie, a gdy rośnie, rozrzut zwiększa się i średnia zaczyna słabiej opisywać całość. Najważniejsze: wynik zawsze ma tę samą jednostkę co dane, więc 5 zł oznacza pięć złotych rozrzutu, a 5 punktów - pięć punktów.
Ta miara nigdy nie schodzi poniżej zera, bo opiera się na kwadratach odchyleń. Im dalej wartości uciekają od środka, tym szybciej rośnie wynik, więc nawet kilka skrajnych obserwacji może zmienić obraz całego zbioru.
Nie ma jednej granicy, która mówi: „to już dobrze”, „to już źle”. Ten sam wynik może być niewielki dla cen mieszkań, a ogromny dla ocen w skali 1-5. Dlatego ja zawsze porównuję go z samą średnią, zakresem danych i kontekstem biznesowym albo badawczym.
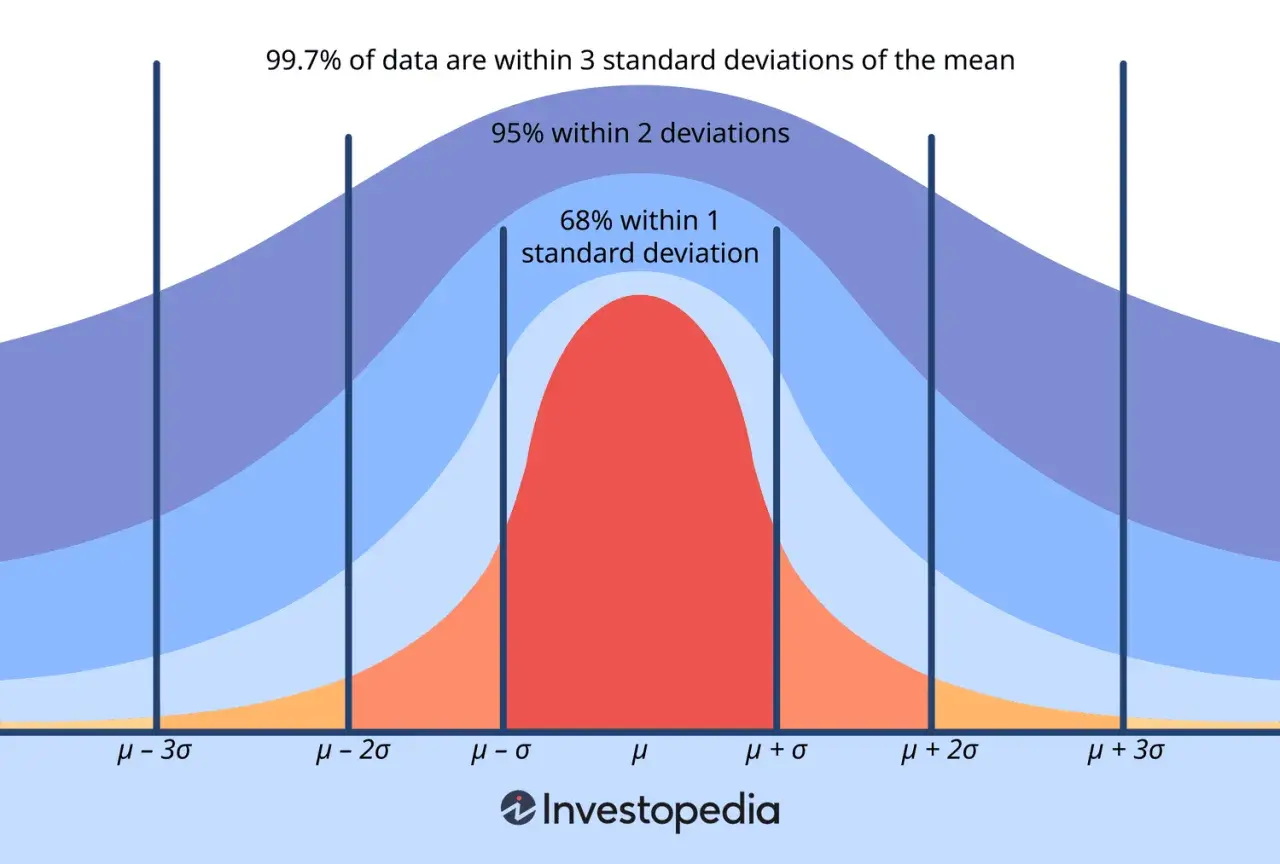
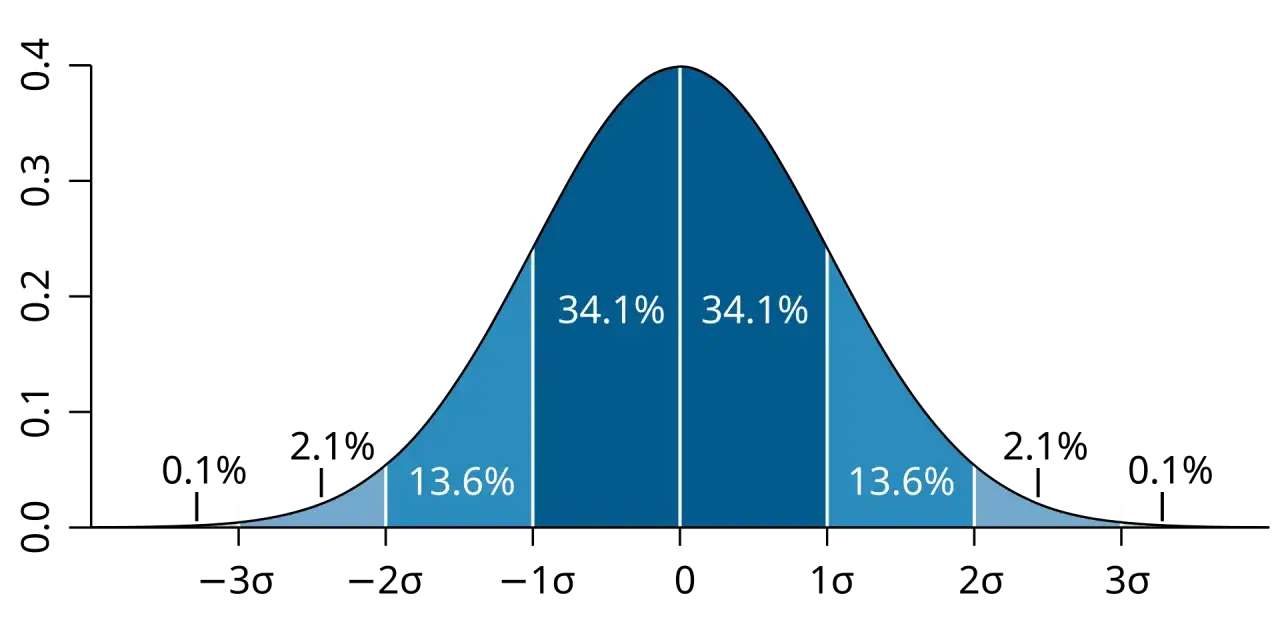
Przy danych zbliżonych do normalnych można w przybliżeniu przyjąć, że około 68% obserwacji mieści się w odległości jednego odchylenia standardowego od średniej. Traktuję to jako wygodną regułę orientacyjną, nie jako uniwersalny wyrok, bo przy silnej asymetrii albo wartościach odstających obraz potrafi się zmienić.
Żeby jednak dobrze z niego korzystać, trzeba jeszcze wiedzieć, jak się go liczy i czemu w próbie pojawia się n-1.
Jak policzyć wynik krok po kroku
Wzór wygląda straszniej niż sama idea. Najpierw liczysz średnią, potem odejmujesz ją od każdej wartości, podnosisz różnice do kwadratu, sumujesz i dzielisz przez liczbę obserwacji albo przez n-1, a na końcu wyciągasz pierwiastek. Sens tego kroku jest prosty: nie chodzi o znak plus czy minus, tylko o skalę odchyłek od środka. W arkuszu kalkulacyjnym to zwykle kilka sekund, ale ręczne przejście przez kroki pomaga zrozumieć, skąd bierze się liczba.
Wzór dla populacji i próby
Dla całej populacji zapisuję to tak: σ = √(Σ(x - μ)² / N). Dla próby używam: s = √(Σ(x - x̄)² / (n - 1)). Ten drugi mianownik jest ważny, bo poprawia lekkie niedoszacowanie rozrzutu, które pojawia się przy liczeniu na wycinku danych.
Przeczytaj również: Jak odnaleźć w sobie motywację i pokonać brak energii do działania
Przykład na prostym zbiorze
Weźmy zestaw: 2, 4, 4, 4, 5, 5, 7, 9. Średnia wynosi 5, a odchylenia od niej to -3, -1, -1, -1, 0, 0, 2 i 4. Po podniesieniu do kwadratu i zsumowaniu dostajemy 32, więc dla populacji wynik to 2, a dla próby około 2,14.
| Wartość | Odchylenie od średniej | Kwadrat odchylenia |
|---|---|---|
| 2 | -3 | 9 |
| 4 | -1 | 1 |
| 4 | -1 | 1 |
| 4 | -1 | 1 |
| 5 | 0 | 0 |
| 5 | 0 | 0 |
| 7 | 2 | 4 |
| 9 | 4 | 16 |
To dobry przykład, bo pokazuje dwie rzeczy naraz: wynik zawsze rośnie wraz z większym rozrzutem i nie da się go poprawnie odczytać bez wiedzy, czy pracujesz na populacji, czy tylko na próbie. Następna pułapka pojawia się wtedy, gdy ktoś widzi samą liczbę i od razu ocenia, czy jest „duża”.
Co oznacza niski, wysoki lub zerowy wynik
Nie ma jednej uniwersalnej skali, ale praktycznie patrzę tak: zero oznacza identyczne wartości, niski wynik mówi o małym rozrzucie, a wysoki sugeruje dużą zmienność albo kilka skrajnych obserwacji. Sama liczba nigdy nie powie wszystkiego, jeśli nie wiesz, na jakiej skali pracujesz.
| Poziom | Co zwykle znaczy | Na co zwrócić uwagę |
|---|---|---|
| 0 | Wszystkie wartości są takie same | Sprawdź, czy to zamierzony efekt, a nie błąd w danych |
| Niski | Wyniki są skupione blisko średniej | To nie zawsze oznacza „lepiej”, bo wszystko zależy od celu analizy |
| Wysoki | Dane są mocno rozproszone | Sprawdź wartości odstające, podziały na grupy i jakość pomiaru |
Jeśli dane przypominają rozkład normalny, można w przybliżeniu oczekiwać, że około 68% obserwacji mieści się w odległości jednego odchylenia standardowego od średniej. Ja korzystam z tej reguły tylko wtedy, gdy rozkład rzeczywiście nie jest mocno skośny, bo inaczej łatwo pomylić skrót myślowy z obrazem całego zbioru.
Dla dwóch serii o tej samej średniej wynik może wyglądać zupełnie inaczej. Zestaw 4, 5, 5, 6, 5 ma mały rozrzut, a 1, 2, 8, 9, 5 pokazuje dużo większą niestabilność, choć średnia w obu przypadkach kręci się wokół 5. To właśnie dlatego sama średnia bywa myląca.
Właśnie tu widać, że liczy się nie tylko liczba, ale też układ danych wokół niej. Następny krok to porównanie tej miary z innymi, które opisują zmienność z trochę innej strony.
Czym różni się od wariancji, rozstępu i współczynnika zmienności
Najczęściej mylone są cztery rzeczy, ale ich role są różne. Wariancja jest matematycznie bardzo wygodna, tylko że ma „kwadratowe” jednostki, więc trudniej ją czytać. Rozstęp jest banalnie prosty, ale bazuje tylko na minimum i maksimum. Współczynnik zmienności robi z rozrzutu miarę względną, więc najlepiej nadaje się do porównań między różnymi skalami.
| Miara | Co pokazuje | Plus | Minus | Najlepsze zastosowanie |
|---|---|---|---|---|
| Wariancja | Średni kwadrat odchyleń | Wygodna w modelach statystycznych | Trudna do intuicyjnego odczytu | Obliczenia i testy statystyczne |
| Rozstęp | Różnicę między min i max | Błyskawiczny do sprawdzenia | Ekstremy mogą go zafałszować | Szybka orientacja |
| SD | Typowy rozrzut wokół średniej | Ma tę samą jednostkę co dane | Wrażliwy na wartości odstające | Opis danych i porównania w obrębie jednej skali |
| CV | Rozrzut względem średniej | Ułatwia porównania między różnymi skalami | Staje się mało użyteczny, gdy średnia jest bliska zeru | Porównywanie zmienności np. kosztów, czasu i wyników |
Jeśli mam porównać dwie grupy o bardzo różnych jednostkach albo bardzo różnych średnich, częściej sięgam po współczynnik zmienności niż po sam rozrzut bezwzględny. Jeśli natomiast chcę po prostu opisać jedną serię danych, odchylenie wokół średniej pozostaje czytelniejsze niż wariancja. To praktyczna różnica, która oszczędza mnóstwo błędnych interpretacji.
Gdzie sprawdza się w analizie danych, a gdzie lepiej wybrać inną miarę
Ta miara najlepiej działa tam, gdzie liczy się spójność wyników: w sprzedaży, jakości produkcji, badaniach ankietowych, analizie czasu pracy albo monitorowaniu postępów w nauce. Jeśli ktoś śledzi codzienny czas skupienia, średnia mówi ile godzin wychodzi przeciętnie, a rozrzut pokazuje, czy plan jest stabilny, czy raz trzyma poziom, a raz rozsypuje się całkiem.
- W finansach pomaga ocenić zmienność wyników, ale sama średnia zwrotu bez rozrzutu potrafi być złudna.
- W edukacji pokazuje, czy grupa ma podobne wyniki, czy są w niej duże różnice.
- W jakości procesów sygnalizuje, czy produkcja lub obsługa działają przewidywalnie.
- W nawykach i rozwoju osobistym pomaga odróżnić realną regularność od jednorazowego zrywu.
Nie używałbym jej jednak jako jedynej miary wtedy, gdy dane są mocno skośne, zawierają pojedyncze skrajne obserwacje albo gdy zbiór lepiej opisuje mediana niż średnia. W takich sytuacjach lepiej dołożyć percentyle, czyli punkty dzielące uporządkowane dane na części, rozstęp międzykwartylowy, czyli szerokość środkowych 50% danych, albo medianowe odchylenie bezwzględne, czyli odporniejszą miarę rozrzutu opartą na medianie. Te narzędzia są mniej wrażliwe na skrajne obserwacje, więc częściej pokazują to, co faktycznie dzieje się w zbiorze.
Na co patrzę, zanim uznam wynik za użyteczny
Zanim uznam wynik za sensowny, sprawdzam trzy rzeczy: skalę danych, obecność skrajnych wartości i to, czy porównuję podobne zbiory. Jedna liczba bez kontekstu bywa tylko ładnym skrótem, a nie odpowiedzią.
- Porównuj tę miarę tylko tam, gdzie jednostka i skala mają sens.
- Sprawdzaj, czy średnia nie jest sztucznie zniekształcona przez pojedyncze skrajne wartości.
- Gdy grupy mają różne średnie, rozważ współczynnik zmienności.
- Gdy dane są skośne, dołóż medianę i percentyle.
- Gdy analizujesz małą próbę, traktuj wynik ostrożnie, bo może się mocno zmienić po dodaniu kilku obserwacji.
Tak pracuję z tą miarą na co dzień: nie jako z samodzielnym werdyktem, ale jako z szybkim sygnałem, czy dane są stabilne, rozchwiane, czy może wymagają innego opisu. Jeśli chcesz podejmować lepsze decyzje na podstawie liczb, właśnie ten prosty nawyk daje najwięcej korzyści.